服务器篇
来自陌陌游戏WIKI
目录
性能压测工具
工具地址:http://clr.igamesofficial.com:9090/loadnode-web/ 备注:账号需要向陌陌技术支持申请
网络诊断工具
工具地址:http://tool.immomogame.com 备注:用于诊断用户终端基础信息&网络情况
运维自动化工具
自动化部署工具-Ansible
使用 Ansible 需要安装什么
1、部署机以及被管理的主机需要安装有 Python 2.6 及以上的版本
2、部署机器上需安装 Ansiblle
3、Ansible 通过 SSH 协议管理服务器。如果使用 Password 的方式登陆被管理的主机,还需安装 SSHPass
Ansible 安装教程
1、通过 Yum 安装 Ansible 最新发布版本
2、SSHPass 安装
源码下载地址:http://sourceforge.net/projects/sshpass/


新手上路
Inventory 文件
Ansible 可同时操作属于一个组的多台主机,组和主机之间的关系通过 inventory 文件配置. 默认的文件路径为 /etc/ansible/hosts
Inventory 文件的格式如下:
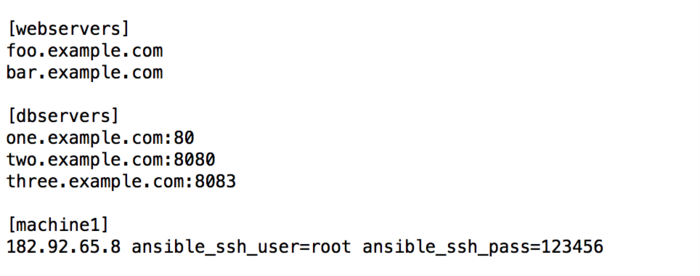
方括号[]中是组名,用于对系统进行分类,便于对不同系统进行个别的管理
如果有主机的 SSH 端口不是标准的22端口,可在主机名之后加上端口号,用冒号分隔
对于每一个 host,还可以配置连接用户名、密码等信息

你的第一条命令
现在ping machine1分组中的所有节点:
$ ansible machine1 -m ping
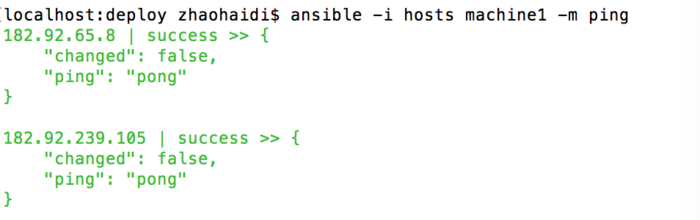
使用 -i 可以指定一个文件作为 Inventory 文件,不是使用 -i 则使用默认路径(/etc/ansible/hosts)中的 Inventory 文件

远程执行 shell 命令
$ ansible machine1 -m shell -a "/bin/echo hello"

命令中,-m 表示模块 -a表示命令 ,ansible支持的模块可以通过 ansible-doc -l 命令来查询。

简单的 Playbooks
当我们配置机器的时候,通常需要在同一时间内做许多操作。Anisble提供了一个工具叫playbooks,playbooks使用YAML文件。
YAML
所有的 YAML 文件开始行都应该是 ---. 这是 YAML 格式的一部分, 表明一个文件的开始.
列表中的所有成员都开始于相同的缩进级别, 并且使用一个 "- " 作为开头(一个横杠和一个空格):

一个字典是由一个简单的 键: 值 的形式组成(这个冒号后面必须是一个空格):

更多 YAML 信息可以查看 http://www.yaml.org/


一个简单的playbook配置如下:


Playerbooks 基础
主机与用户
你可以为 playbook 中的每一个 play,个别地选择操作的目标机器是哪些,以哪个用户身份去完成要执行的步骤
hosts 行的内容是目标机器,remote_user 就是账户名
---
- hosts: machines
remote_user: root
Tasks
每一个 play 包含了一个 task 列表(任务列表).每一个 task 必须有一个名称 name。
这样在运行 playbook 时,从其输出的任务执行信息中可以很好的辨别出是属于哪一个 task 的。
下面是一种基本的 task 的定义,service moudle 使用 key=value 格式的参数,这也是大多数 module 使用的参数格式:
tasks:
- name: make sure apache is running
service: name=httpd state=running
比较特别的两个 modudle 是 command 和 shell ,它们不使用 key=value 格式的参数,而是这样:
tasks:
- name: disable selinux
command: /sbin/setenforce 0
Handlers
Ansible还支持设置handlers,handlers是在执行tasks之后服务器发生变化之后可供调用的handler,使用起来如下:


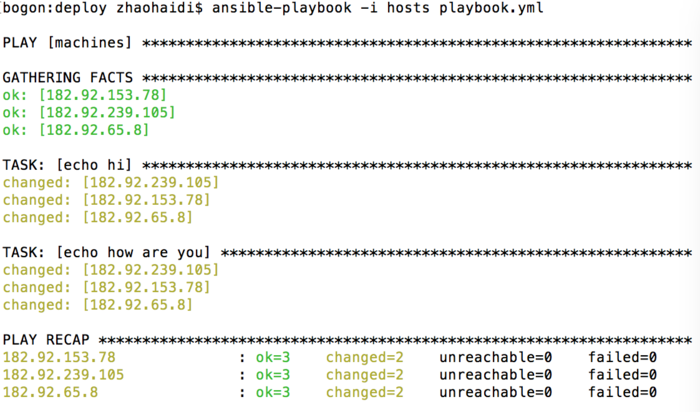
执行一个 playbook
playbook.yml 文件如下:

运行一个playbook:ansible-playbook playbook.yml


Ansible 进阶资料
Ansible 官方文档:http://docs.ansible.com/ansible/index.html Ansible 中文文档:http://www.178linux.com/doc/ansible/docs/intro.html DevOps 更多资料请参看:https://github.com/geekwolf/sa-scripts/blob/master/devops.md
自动化监控工具-Zabbix
一、Zabbix基础知识
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。
zabbix可以监控:
通过zabbix-agent,监控linux系统的cpu、内存、网卡流量、磁盘io,服务,端口等
结合IPMI,监控物理服务器风扇的转速,温度
通过snmp,监控网络设备的网络状态、流量等的监控
结合libvirt,监控kvm虚拟机
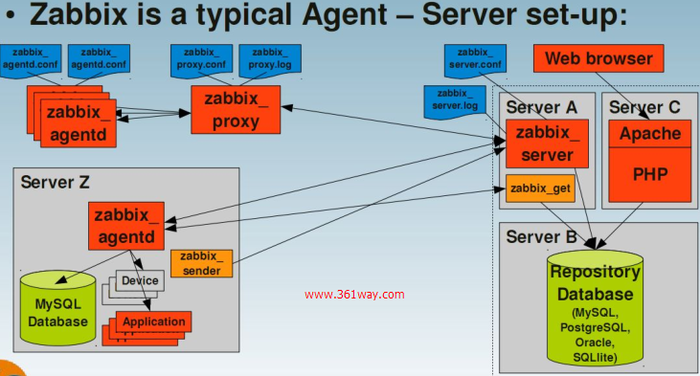
1.1 Zabbix进程构成
zabbix_server:zabbix服务端守护进程。
zabbix_agentd:客户端守护进程,此进程收集客户端数据,例如cpu负载、内存、硬盘使用情况等。
zabbix_get:zabbix工具,单独使用的命令,通常在server或者proxy端执行获取远程客户端信息的命令。
zabbix_sender:zabbix工具,用于发送数据给server或者proxy,通常用于耗时比较长的检查。
zabbix_proxy:zabbix代理守护进程。功能类似server,唯一不同的是它只是一个中转站,它需要把收集到的数据提交/被提交到server里。
zabbix_java_gateway:类似agentd,但是只用于Java方面。
备注:zabbix_agentd、zabbix_get、zabbix_sender、zabbix_proxy、zabbix_java_gateway的数据最终都汇总到server。当然不是数据都是主动提交给zabbix_server,也有的是server主动去取数据。
关系图:

1.2 Zabbix 3.0安装需求
1、硬件需求:Zabbix对硬件需求极低,常用服务器(8核心16G)即具有监控1w+以上服务器的能力;具体可参照官方文档,不在此赘述。
2、操作系统:支持操作系统极其丰富;但是window平台,只能部署zabbix_agentd。
3、软件需求:PHP 5.4.0或以上(PHP v7暂不支持)、Apache 1.3.12或以上以及Mysql 5.03或者以上。
备注:特定监控项,需要另外安装特定支持,具体可参考:https://www.zabbix.com/documentation/3.0/manual/installation/requirements
1.3 时间同步
请确保你所有的服务器时间都是正确的,为了确保时间ok,请在crontab里面加上定时时间同步。
# crontab -l
00 00 * * * /usr/sbin/ntpdate -u cn.pool.ntp.org
二、Zabbix 3.0安装(阿里云ECS--Centos 7)
2.1 Zabbix-Agent安装
1、安装相关依赖库
# yum -y install unixODBC
2、Zabbix-Agent安装
# rpm -ivh http://repo.zabbix.com/zabbix/3.0/rhel/7/x86_64/zabbix-agent-3.0.3-1.el7.x86_64.rpm
3、编辑zabbix-agent的配置文件
# vim /etc/zabbix/zabbix_agentd.conf
Server=127.0.0.1
ServerActive=127.0.0.1
Hostname=Zabbix.agent.1(客户端自助注册时,server端显示的名字)
其中Server和ServerActive都指定zabbixserver的IP地址,不同的是,前者是被动后者是主动。
也就是说Server这个配置是用来允许127.0.0.1这个ip来我这取数据。
而serverActive的127.0.0.1的意思是,客户端主动提交数据给他。
4、在iptables中放行10050端口
# systemctl restart firewalld
# firewall-cmd --permanent --add-port={80/tcp,10050/tcp}
# firewall-cmd --reload
5、关闭selinux
# sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
# setenforce 0
6、配置开机启动项
# systemctl enable zabbix-agent
7、启动
# systemctl start zabbix-agent
2.2 Zabbix-Server安装
1、Apache HTTP Server 安装、启动以及设置开机启动
# yum install httpd -y
# systemctl start httpd
# systemctl enable httpd
2、mysql 安装、启动以及设置开机启动
# yum install mariadb-server -y //如果已安装可以省略
# systemctl start mariadb.service //启动服务
# systemctl enable mariadb.service //开机启动服务
# mysql -u root -p
3、php安装
# yum install php php-mysql php-gd php-pear -y
4、添加Zabbix仓库
# yum install epel-release
# rpm -ivh http://repo.zabbix.com/zabbix/3.0/rhel/7/x86_64/zabbix-release-3.0-1.el7.noarch.rpm
5、安装Zabbix Server:
# yum install zabbix-server-mysql zabbix-web-mysql
6、创建msql数据库和用户(需设置编码格式utf-8)
create database zabbix_db default charset utf8;
# cd /usr/share/doc/zabbix-server-mysql-3.***/
# gunzip create.sql.gz
# mysql -u root -p zabbix_db < create.sql
7、修改zabbix_server配置文件
# vim /etc/zabbix/zabbix_server.conf
修改为如下参数:
DBHost=localhost
DBName=zabbix_db
DBUser=***
DBPassword=***
8、修改php配置
# vim /etc/php.ini
修改为如下参数:
max_execution_time = 600
max_input_time = 600
memory_limit = 256M
post_max_size = 32M
upload_max_filesize = 16M
date.timezone = Asia/Shanghai
9、修改zabbix.conf配置文件
# vim /etc/httpd/conf.d/zabbix.conf
更新时区:
php_value date.timezone Asia/Shanghai
10、防火墙配置
# systemctl restart firewalld
# firewall-cmd --permanent --add-port={80/tcp,10051/tcp}
# firewall-cmd --permanent --add-service=http
# firewall-cmd --reload
11、关闭selinux
# sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
# setenforce 0
12、服务器启动
# systemctl restart httpd
# systemctl restart zabbix-server
13、使用浏览器访问Zabbix Web接口:
http://your_doman_or_IP/zabbix/

14、通过控制台配置Zabbix
按照提示配置数据库即可,安装完成后,重定向到zabbix控制台登录页面. 输入用户名和密码,默认的用户名和密码为Admin/zabbix.
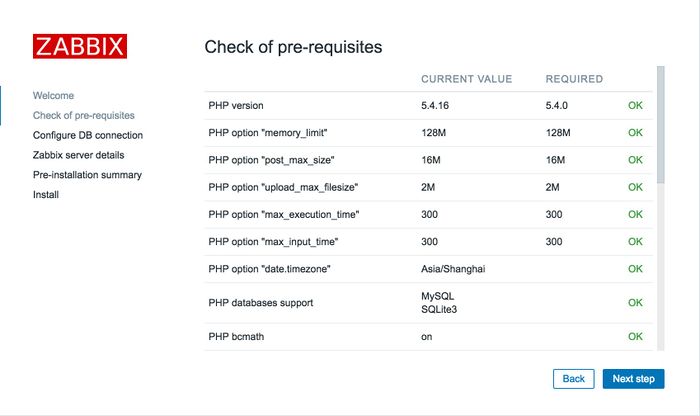
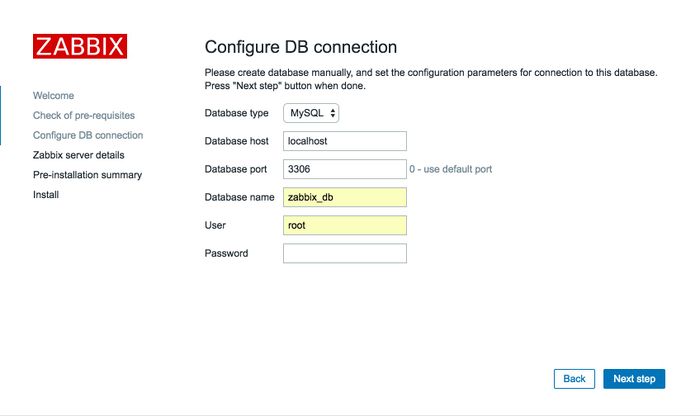
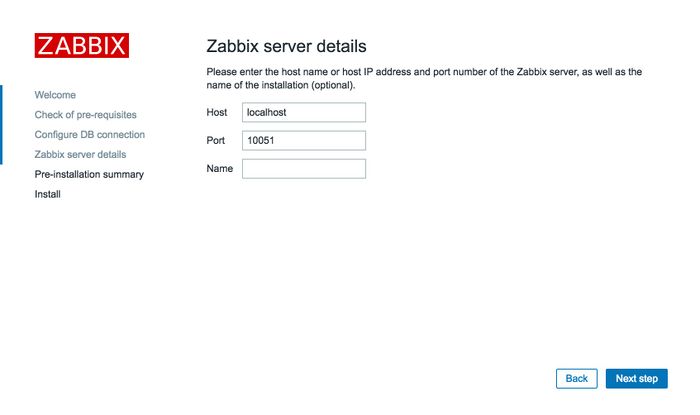
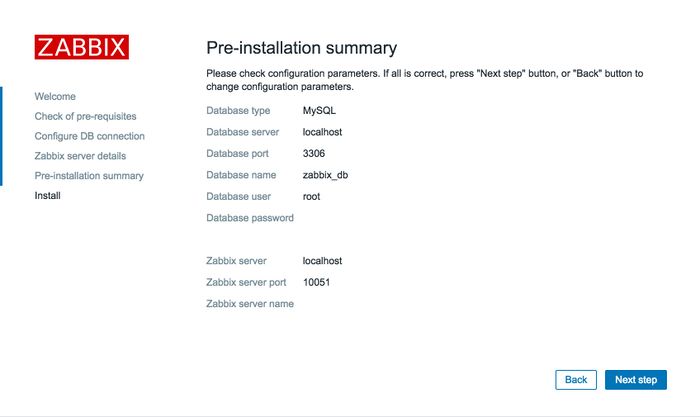







三、Zabbix 3.0快速上手
3.1 监控第一台服务器
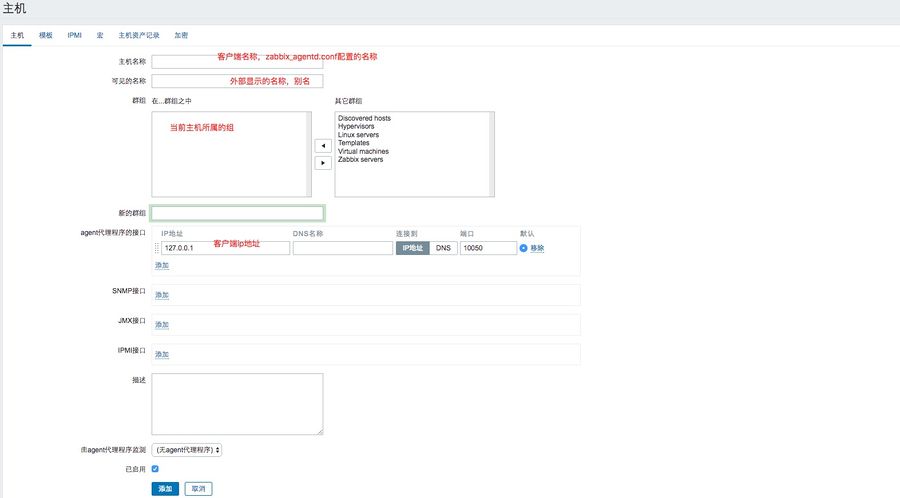
1、创建主机
configuration(配置)-->Hosts(主机)-->Create host(创建主机)
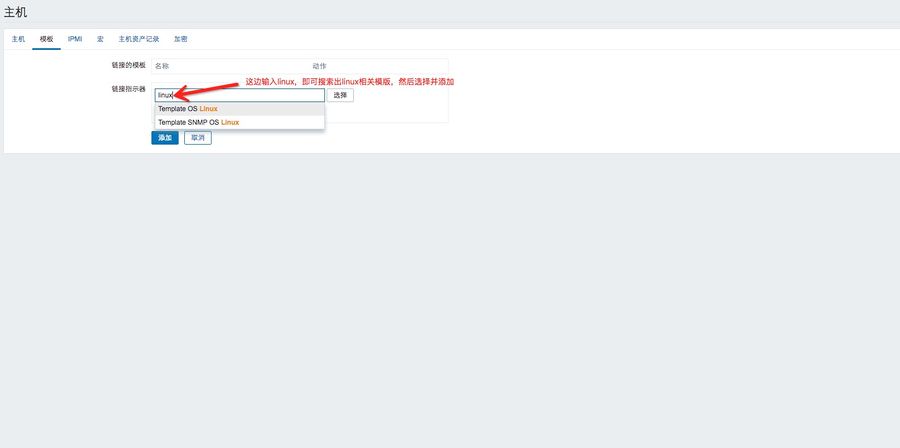
2、链接监控模版
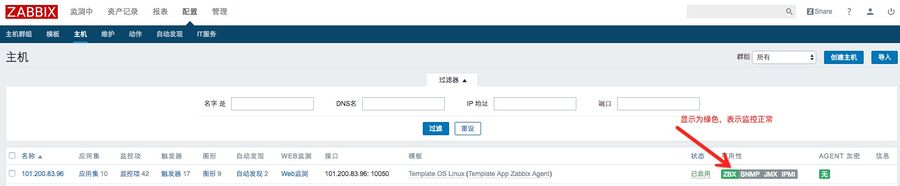
3、查看主机列表
绿色的Z表示成功的监控了这台客户端,如果是红色Z表示失败,此时将鼠标移动到红色Z上,会有具体的提示
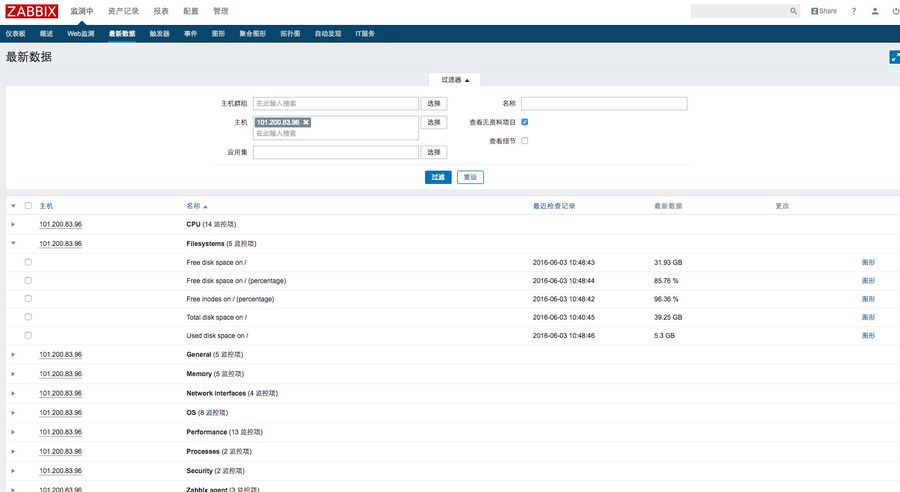
4、查看监控数据
第一台主机添加完成之后,我们便可以查到最新的数据,例如cpu、内存、硬盘等情况




3.2 创建zabbix模版
zabbix模板中可以包含监控项、触发器、web监控、图表等等项目,一一创建这些项目之后,在后续的主机只需要套用这个模板,那么主机便可以监控模板里面所配置的监控项目。
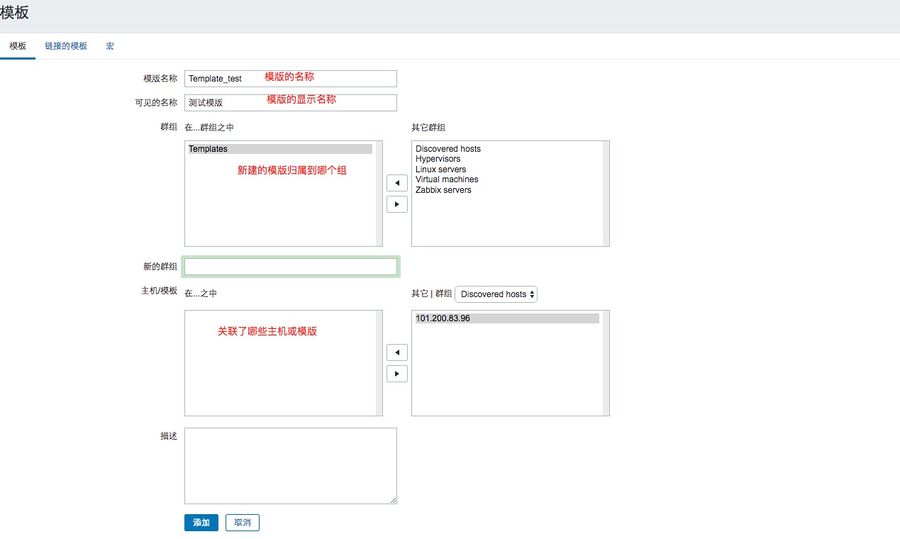
1、创建模版
点击Configuration(配置) ---Templates(模板)---create template(创建模板)
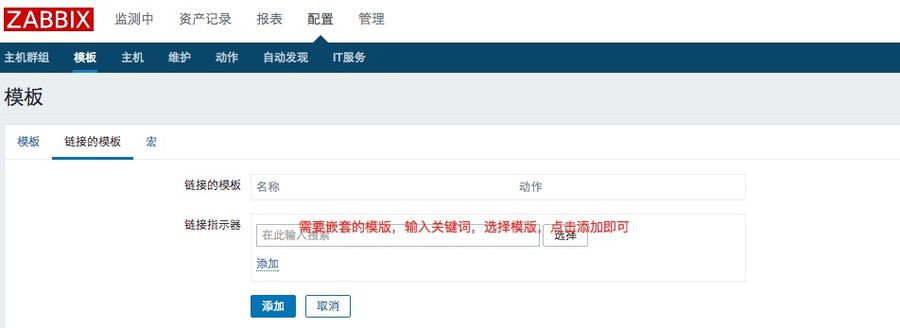
2、嵌套模版
模板嵌套,是一个继承的关系。例如我们定义了一个基础模板,里面item有cpu、内存、硬盘、网卡等等基本信息监控,我们有需要定义个MySQL与WEB监控模板,那么这两个模板分别嵌套这个基础模板即可,而不需要重复定义监控项。
3、创建监控项
点击模版中的监控项,点击创建监控项。具体参数参见截图。
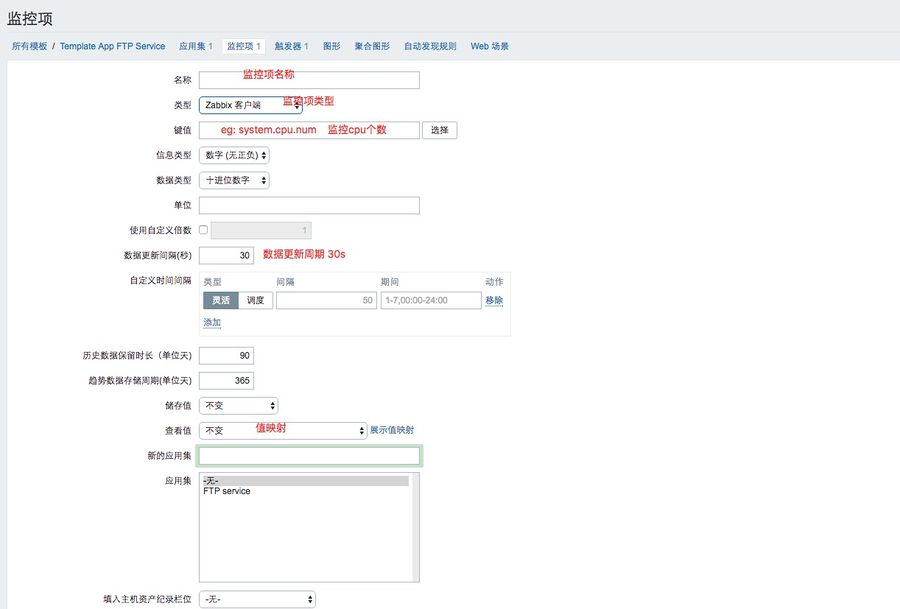
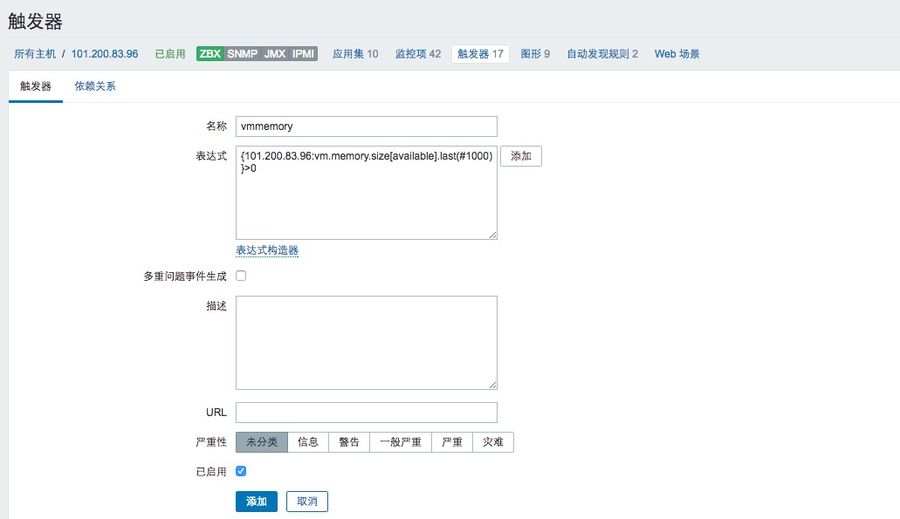
4、创建触发器




3.3 zabbix 聚合图形配置
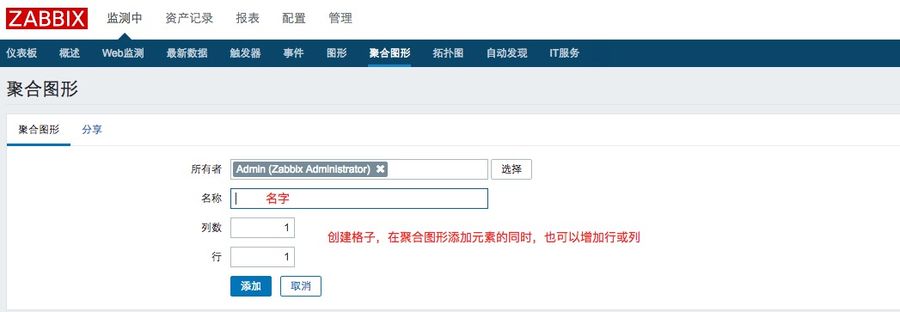
1、创建聚合图形
点击检测中--聚合图形--创建聚合图形,输入如下信息:
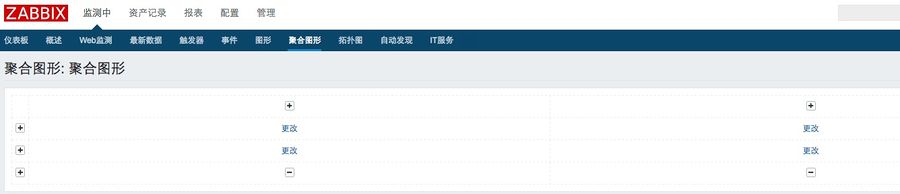
2、添加聚合图形元素
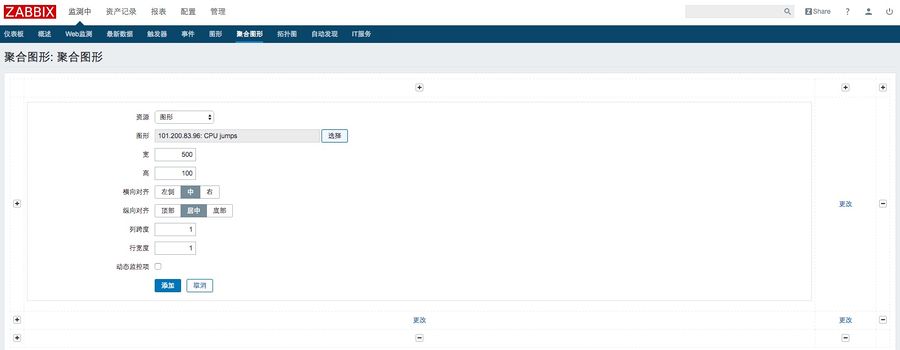
3、查看聚合图形
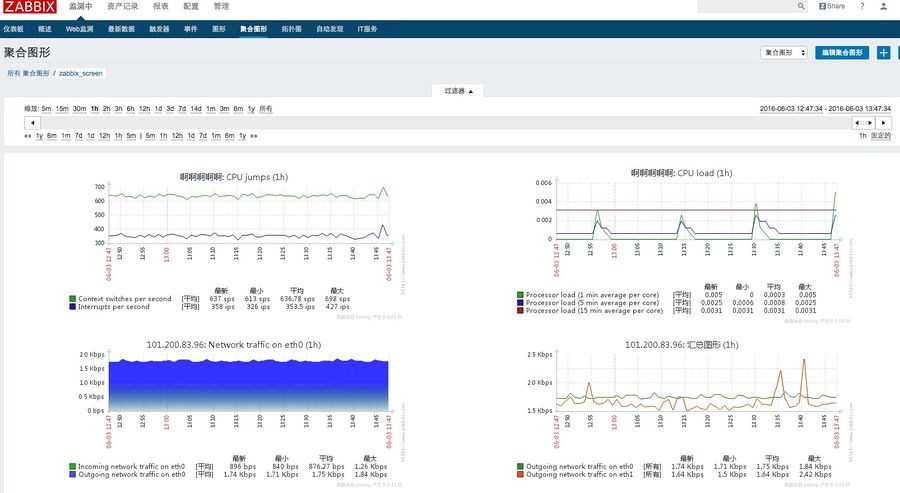




3.4 zabbix 事件通知
1、创建事件通知
点击配置--动作--触发器--创建触发器
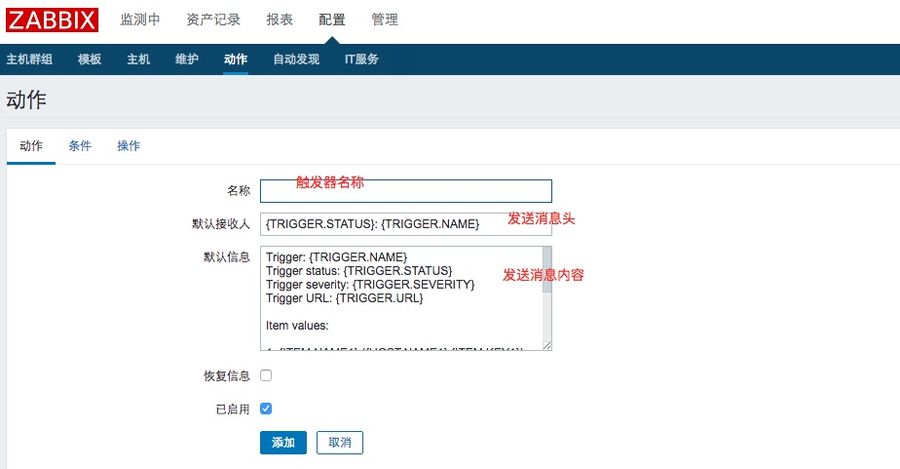
2、事件通知条件
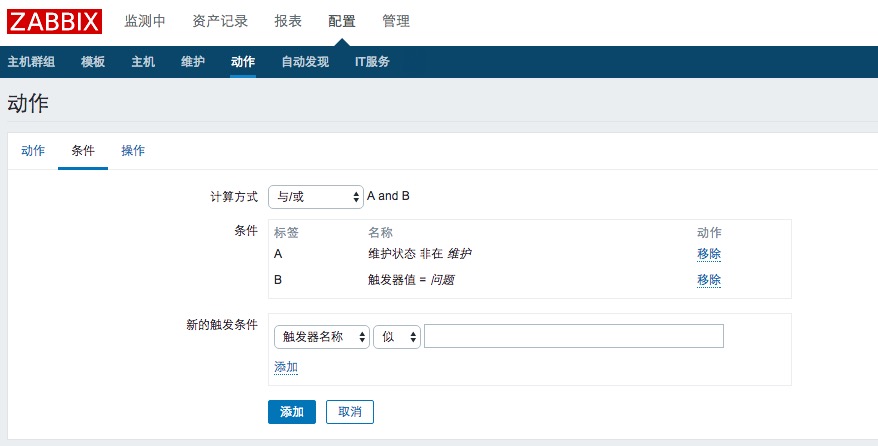
3、事件通知操作
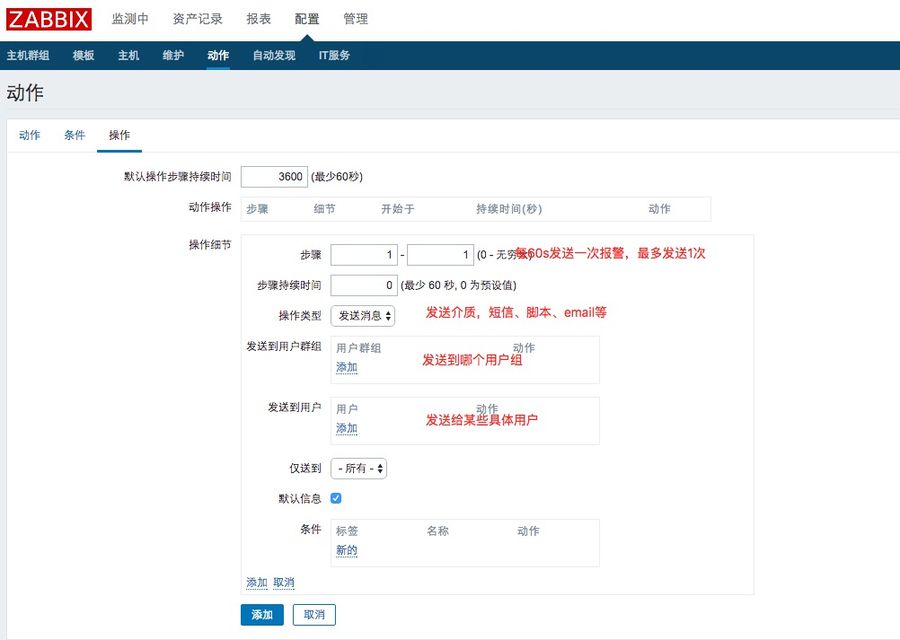



四、zabbix使用举例
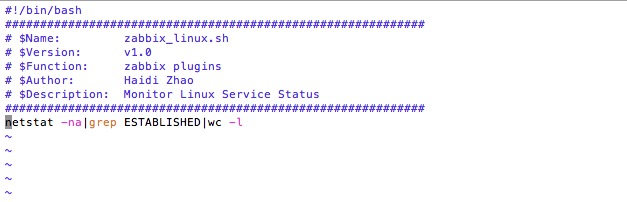
4.1 Zabbix 监控tcp连接数
1、写监控,脚本如下
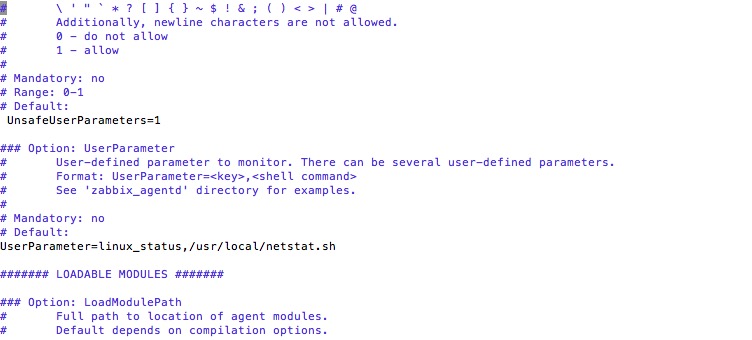
2、把脚本放到需要监控的服务器上,并在zabbix_agent.conf中进行配置, 并重启zabbix客户端
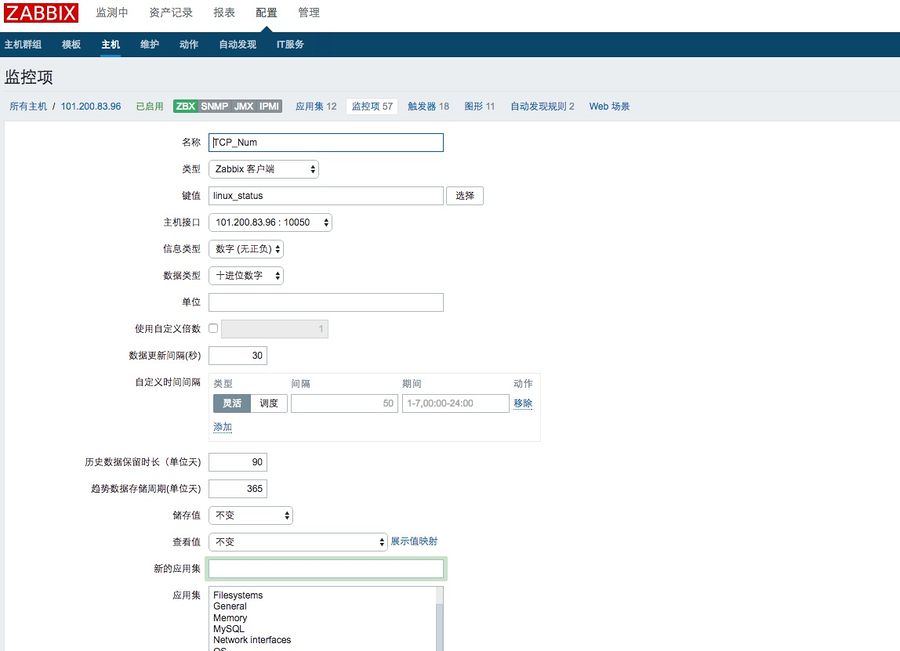
3、在zabbx服务端的web中添加对于tcp链接数的监控项目
4、添加监控图像
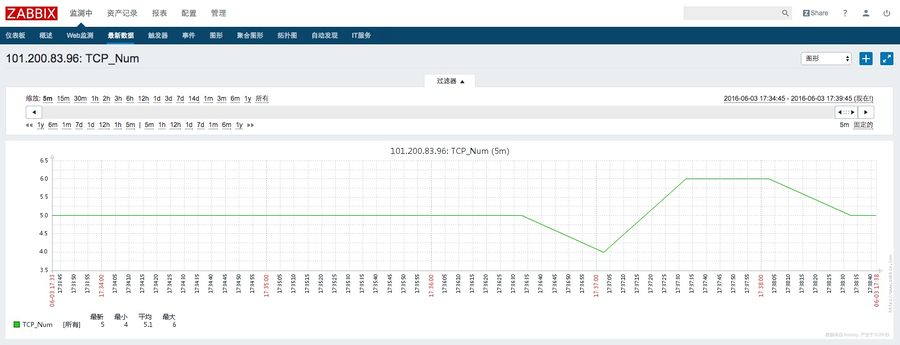




五、常见问题
5.1 Zabbix 3.0 中文乱码问题
zabbix 3.0默认支持中文,但把语言设置成中文后,会发现图形中的中文都乱码了。


解决方案:1、确认数据库是否使用 utf8编码;2、下载微软雅黑字体,改名为msyh.ttf传入**/zabbix/fonts 目录下
编辑**/zabbix/include/defines.inc.php配置文件
define('ZBX_FONT_NAME', 'msyh');
define('ZBX_GRAPH_FONT_NAME', 'msyh')
刷新页面后,图形中乱码消失
六、Zabbix参考资料
Zabbix从入门到精通:http://www.ttlsa.com/monitor/zabbix/ Zabbix 3.0 官方文档:https://www.zabbix.com/documentation/3.0/start
NRT日志监控收集分析平台
一、平台架构
日志监控平台的架构,如下图所示:
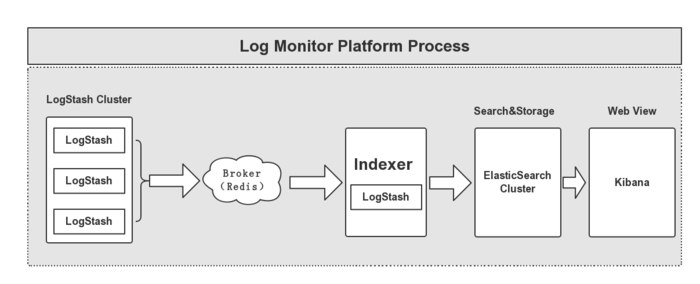

通过上图,我们可以清晰的看到日志平台整个流向过程。首先,多个独立的Agent,这里就是图左边的三个LogStash节点,他们负责收集不同来源的数据,由一个Indexer负责进行汇总和分析数据,在这个当中有一个中间过程,这里我们使用了Broker,用Redis来实现这部分功能,其作用充当一个缓冲区,之后由ElasticSearch负责存储和搜索数据,最后由前段的Kibana可视化我们收集的数据。
二、部署
2.1 Logstash部署
1、安装Logstash依赖
安装JDK7及以上版本(这里不再讲述JDK安装步骤)
2、下载最新版本的 logstash
# curl -L -O https://download.elastic.co/logstash/logstash/logstash-2.3.2.tar.gz
# tar -zxvf logstash-2.3.2
# cd logstash-2.3.2/
3、配置Logstash配置文件
新建logstash.conf文件,配置规则参见官方文档
4、启动Logstash
# nohup ./logstash -f logstash.conf &
2.2 Elasticsearch部署
1、安装Elasticsearch依赖
安装JDK7及以上版本(这里不再讲述JDK安装步骤)
2、创建elsearch用户组及elsearch用户
# groupadd elsearch
# useradd elsearch -g elsearch -p elasticsearch
3、下载最新版本的 Elasticsearch
# curl -L -O https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.3/elasticsearch-2.3.3.tar.gz
# tar -zxvf elasticsearch-2.3.3.tar.gz
# cd elasticsearch-2.3.3/
4、更改elasticsearch文件夹及内部文件的所属用户及组为elsearch
# chown -R elsearch:elsearch elasticsearch-2.3.3
5、切换到elsearch用户再启动
# su elsearch
# ./elasticsearch -d
6、打开另一个终端进行测试
# curl 'http://localhost:9200/?pretty'

2.3 Kibana部署
1、下载最新版本的 Kibana
# curl -L -O https://download.elastic.co/kibana/kibana/kibana-4.5.1-linux-x64.tar.gz
# tar -zxvf kibana-4.5.1-linux-x64.tar.gz
# cd kibana-4.5.1-linux-x64/
2、修改Kibana配置文件kibana.yml
elasticsearch_url: "http://10.211.55.18:9200"
3、启动Kibana
# nohup ./kibana &
访问:http://YOURDOMAIN.com:5601

三、使用
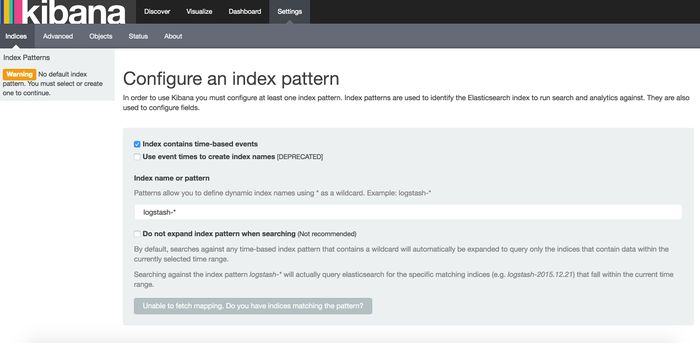
1、让 kibana 连接到 elasticsearch
在开始用 Kibana 之前,你需要告诉它你打算探索哪个 Elasticsearch 索引。第一次访问 Kibana 的时候,你会被要求定义一个 index pattern 用来匹配一个或者多个索引名。
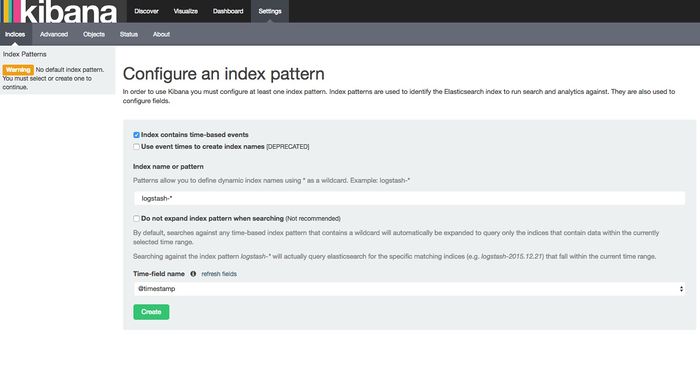
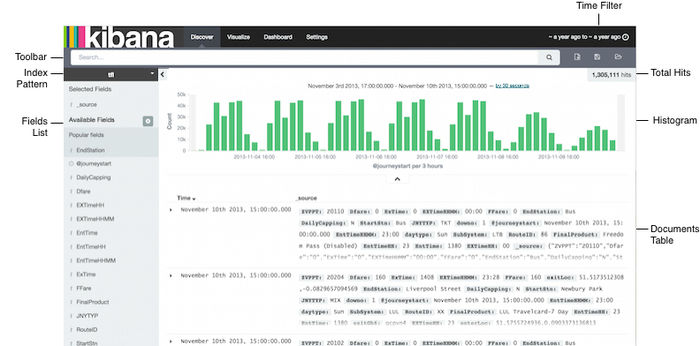
2、discover 功能
Discover 标签页用于交互式探索你的数据。你可以访问到匹配得上你选择的索引模式的每个索引的每条记录。
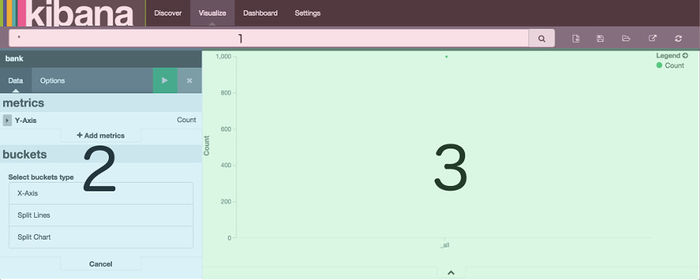
3、Visualize 功能
第 1 步: 选择可视化类型;第 2 步: 选择数据源;第 3 步: 可视化编辑器
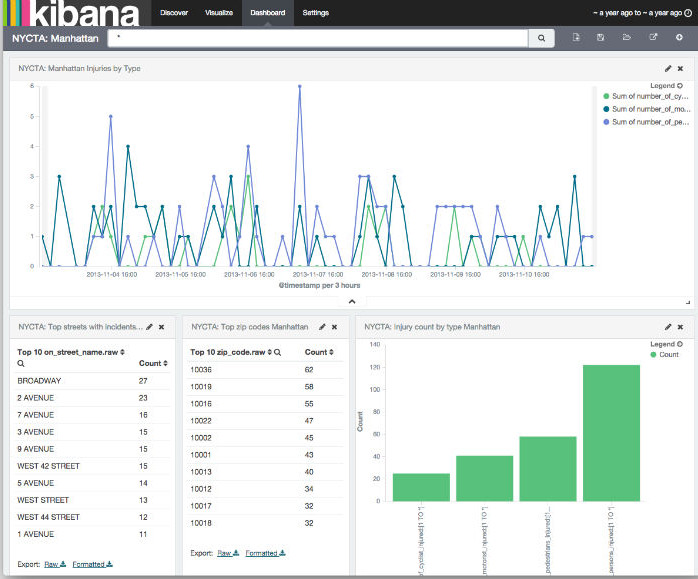
4、Dashboard 功能
一个 Kibana dashboard 能让你自由排列一组已保存的可视化。




四、相关资料
Elasticsearch 权威指南:http://es.xiaoleilu.com/index.html The Logstash Book:https://www.logstashbook.com/
Apache Kafka:分布式消息系统
一、Kafka独特设计
Kafka将消息以topic为单位进行归纳。
将向Kafka topic发布消息的程序成为producers。
将预订topics并消费消息的程序成为consumer。
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker。
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
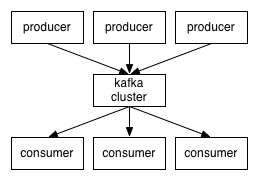
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。

二、部署
1、下载Kafka
点击下载最新的版本并解压。
# tar -xzf kafka_2.9.2-0.8.1.1.tgz
2、启动Zookeeper服务
Kafka用到了Zookeeper,所以首先启动Zookeeper
# bin/zookeeper-server-start.sh config/zookeeper.properties &
3、启动Kafka
# bin/kafka-server-start.sh config/server.properties
4、创建topic
创建一个叫做“test”的topic,它只有一个分区,一个副本。
# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
5、查看topic
可以通过list命令查看创建的topic:
# bin/kafka-topics.sh --list --zookeeper localhost:2181
三、相关资料
Kafka中文教程:http://orchome.com/kafka/index